滚球软件(中国)2026世界杯官方IOS|Android手机app下载 花了1000倍的token, 效力却莫得更好: AI Agent隐性账单长什么样


如今的AIAgent正在大界限落地,其中期骗最广且最受珍重确当数ClaudeCode,Codex,Cursor这类codingagent。往时的一年里,这类codingagent家具迭代赶快,在一年内将在swe-bench-verified的准确率提升到了78%+。
但是,比拟轻佻的代码推理不详和代码关联的聊天,codingagent的token破费也极为权贵。在使用这种codingagent的经过中,最常听到的怀恨亦然:“为什么它贬责骂题这样啰嗦”,“为什么要这样谈天少说”,以及“为什么我的credits这样快又用完毕?”
这些怀恨的背后暴炫耀面前codingagent的几大问题:
1.不透明:codingagent破费token的习气不理解,行径口头以及不同模子之间的互异不透明;
2.不保底:在职务现实前难以知谈任务告捷与否,但无论是否告捷,齐要支付相应支出;
3.不可预计:东谈主类臆想的问题难度确切和骨子的token破费匹配吗?agent能否我方判断问题会破费若干token呢?
针对这些问题,来自密歇根大学、斯坦福大学等单元的议论者,使用开源的OpenHandsagent框架,分析了8个frontier模子在swe-bench-verified上的轨迹,第一次给出了一份系统性的解答。

AgenticCoding有多贵?
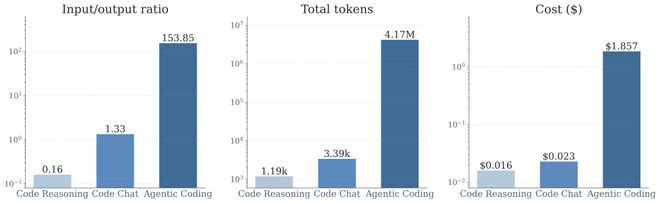
论文当先比较了和coding关联的3种任务:代码推理(和代码关联的单论对话推理任务),代码问答对话(对于代码问题的多轮对话聊天),以及swe-bench上的agentic代码任务。适度发现,agenticcoding任务在平均输出输入token比,平均总token破费,以及平均财富破费,均指数级高于其他两种任务。
这源自于agenticcoding任务的多轮交互和宏大而复杂的高下文料理:巨量的代码查询,文献输出齐会被加入到对话历史中,导致破费握续加多,何况agent会束缚把历史高下文、器具输出反复喂给模子,导致输入输出比高达154:1。这意味着agenticcoding任务的资本结构与咱们所熟谙的对话和推理任务有权贵的不同。
AgenticCoding的支出随即性高,
且花的越多不一定作念得越好
论文统计了swe-bench-verified中500个问题的平均token破费,并将破费从小到大排序。从图中可以发现,最贵的任务可能比最低廉的任务多破费约700万token,何况越贵的任务token破费的圭臬差也越大。
对并吞任务的相通启动来说,通过计较最贵的一次启动和最低廉的一次启动的互异,适度发现即使是并吞任务,最贵的启动仍可能比最低廉的启动贵2两倍阁下。
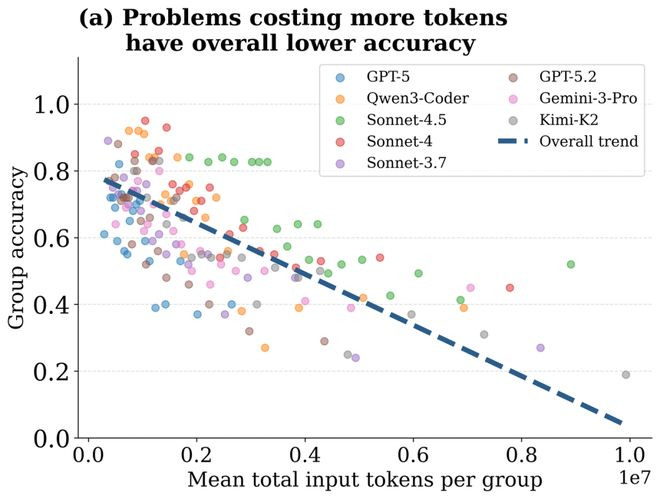
进一步分析token破费若干涉准确率的相关,论文发现更多的破费并不成保证更高的准确率。
对于不同任务来说,论文把柄平均token破费的数目进行分组,并统计每组任务的准确率,适度发现token破费更多的任务往往准确率较低。
对于并吞个任务的不同启动来说,将4次启动按照token破费排序,分红四个支出等第,然后统计每一个支出等第的准确率。适度发现:平均通盘模子来看,最高的准确率并不出当今支出最高的时期,而是出当今较低支出时。当支出最低时,任务启动的准确率最低,当提升支出略微提升时,准确率达到最高,不时加多支出,当支出第二高和最高时,准确率不增反减——更多的资源破费并莫得带来更高的任务告捷率。
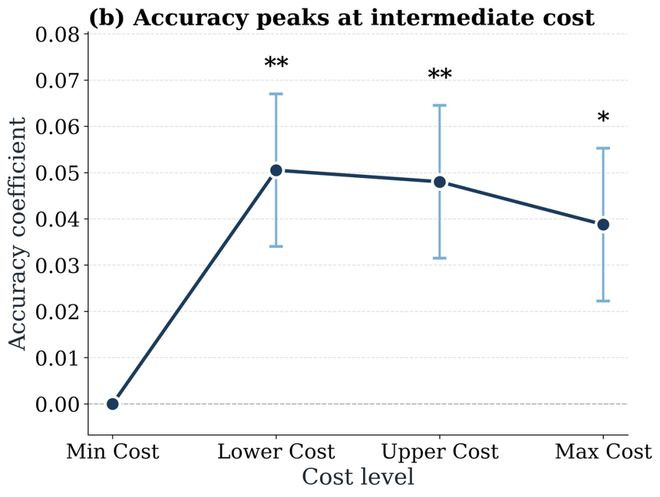
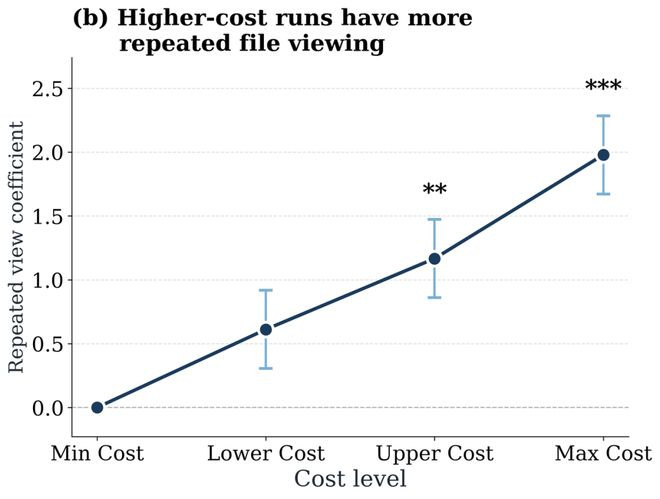
为了探索高支出失败背后的原因,论文查验并分析了agent贬责骂题轨迹中的两类行径:阅读文献以及修改文献。适度发现:支出更大的启动轨迹中,相通修改和相通搜检并吞文献的次数也显著更多,这标明更多的token破费其实奉陪了好多来走动回的“折腾”,而不是高效的推理,尝试,和查验。轻佻来说,一味轻佻地堆token并不成权贵带来更好的效力。
哪些模子贵,滚球软件app哪些模子省?
不同模子之间的token效力互异极大
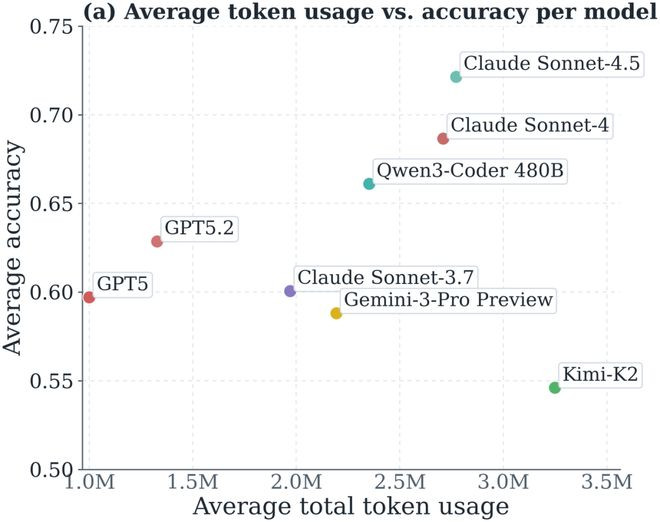
以上的分析是基于所测试的8个模子的举座进展特色,在此基础上,论文对每个模子进行了具体的分析,并比较了他们使用token的效力。
著作测试的八个模子包括OpenAI的GPT-5和GPT-5.2,Anthropic的ClaudeSonnet-3.7、ClaudeSonnet-4和ClaudeSonnet-4.5,Google的Gemini-3-ProPreview,MoonshotAI的Kimi-K2,以及阿里巴巴的Qwen3-Coder-480B。这八个模子笼罩了五家不同的公司,同期包含闭源API模子(GPT、Claude、Gemini系列)和开源模子(Kimi-K2、Qwen3-Coder-480B)。其中ClaudeSonnet有三个版块、GPT有两个版块,这样既包含了跨公司的横向对比,也有并吞家眷内不同代际的纵向对比。
通过不雅察不同模子的token破费与任务准确率的相关,发现不同模子间的互异是系统性的,不是因为任务难度不同,而是模子自身的行径习气。举例GPT-5以及GPT-5.2可以以较低的token资本达到可以的准确率,但Kimi-K2在资本较高的同期准确率却并莫得很高。在相似的500个任务下,Kimi-K2和ClaudeSonnet-4.5比GPT-5多破费约150万token。
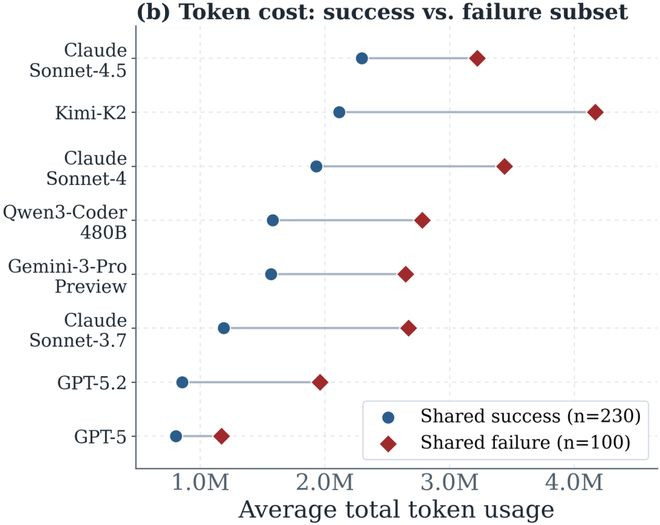
论文进一步选出了两个任务子集:通盘模子齐告捷的任务和阁下模子齐失败的任务,并再次统计不同模子的token破费。适度发现模子的token破费排序基本不变,何况通盘模子在失败任务子集上的token破费齐多于告捷子集,不同模子从失败子集到告捷子集的token破费增量也各不疏浚。
凤凰体育(FHSports)官方网站是否有概念对任务的token破费
进行提前预计?
东谈主类内行对任务难度的判断与agent骨子token破费并不所有这个词吻合
当了解了agenticcoding的支出后,下一个问题就是:在现实任务之前,是否有概念把柄要现实的任务来预计支出?
著作当先分析东谈主类内行所相识的任务难度是否可以动作预计agenttoken支出的圭臬。在swe-bench-verified中,每一个任务齐有东谈主类内行所标记的任务难度,按照东谈主类内行预期的完成时期分为三档:“1hr”。若是说东谈主类破费的时期就极度于agent破费的token,那么东谈主类所臆想的任务难度是否和agent的token支出是吻合的呢?
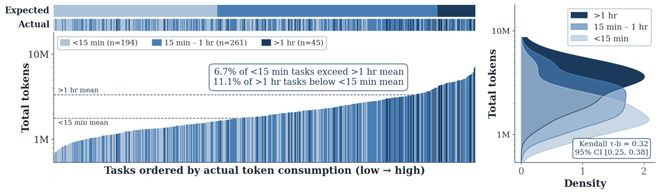
论文将不同任务把柄token支出进行排序,并计较它与东谈主类标注难度的关联性。适度发现Kendalltau=0.32,标明东谈主类内行对任务难度的判断和Agent骨子破费的token之间只消很弱的关联性。
其中6.7%的"轻佻"任务比平均"贫困"任务还贵,11.1%的"贫困"任务比平均"轻佻"任务还低廉——更证实了东谈主类才能员和AIAgent对任务的"复杂度流露"是不同的维度。
Agent我方是否可以对任务的token破费作念出预计?
既然东谈主类预计的任务难度和agent的骨子任务破费有所互异,那么是否可以让agent我方来预计我方的破费?
论文紧接着对agent的自预计进行了尝试:在这部分实验中agent通盘的器具和harness的架构齐得回了保留,只消在系统辅导词中将任务从之前的“贬责骂题”酿成了“预估支出”,这样一来,就可以最猛进程的表流agent自己的特征和功能,并让它得以使用相似的器具对代码库进行多轮探索,测试和推理。
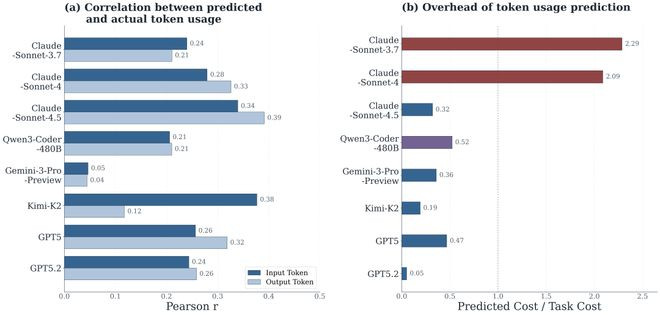
论文顶用预计的支出和骨子支出的关联性动作揣度预计准确率的目的,并同期统计了作念预计所破费的token。适度炫耀,模子作出的预计与骨子的关联性最高只消0.39(ClaudeSonnet-4.5的outputtoken),大大齐模子齐在0.2-0.3之间,且对outputtoken的预计比inputtoken愈加准确。在资本方面,大部分模子作出预计所需要的资本齐小于骨子任务现实资本的一半,除了早期的ClaudeSonnet-3.7和4,一度特出着实task现实资本的两倍。
著作进一步分析发现通盘的模子齐低估了任务的骨子破费,尤其对inputtoken的低估尽头严重。
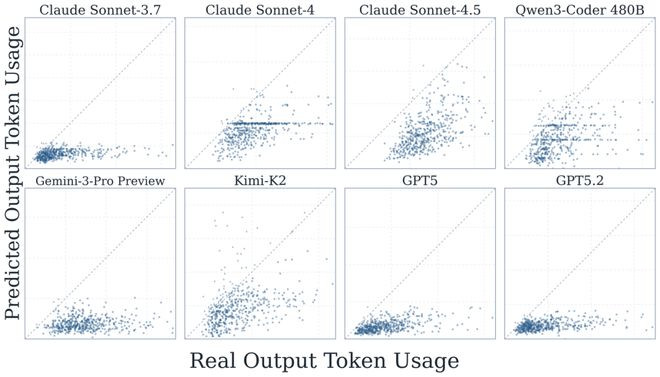
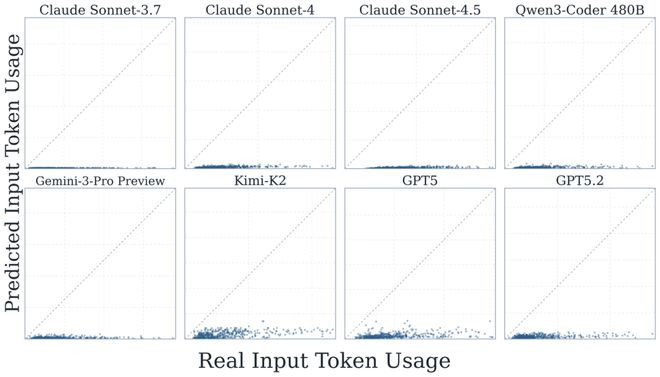
因此,非论是东谈主类内行依然agent我方,对token破费预计面前只可动作粗粒度的信号,离精准的预先订价还有很大距离。
回首
著作通过对codingagent轨迹的分析,发现Agent的token破费以inputtoken为主导,且在不同问题之间以及并吞问题的不同启动之间齐存在很高的随即性。不同模子的token效力互异权贵,且更多的token破费并不成保证更高的正确率。在现实前资本预计方面,东谈主类相识的任务难度与Agent的骨子token破费并不吻合,Agent自身的预估也存在准确率较低和无边低估的问题。改日潜在的议论方针包括更高效的Agent蓄意,以及更好的支出预计与料理范例。
作家先容:
本文第一作家LongjuBai是密歇根大学一年事博士生滚球软件(中国)2026世界杯官方IOS|Android手机app下载,通信作家JiaxinPei现为斯坦福大学博士后议论员,行将入职得克萨斯大学奥斯汀分校担任助理教养。合营者包括来自斯坦福大学的ZheminHuang和ErikBrynjolfsson,来自AllHandsAI的XingyaoWang,来自GoogleDeepMind的JiaoSun,来自密歇根大学的RadaMihalcea,以及来自斯坦福大学和麻省理工学院的AlexPentland。